别着急,坐和放宽
之前有一个需求: "我需要编写一段程序来从一个二进制设备配置文件中,查找到设备的
IP、name、mask等"。查了一些资料后,我计划先用一个已知name字段的设备,从其配置文件中找对应的二进制字段,进而分析确定这些信息的映射关系。但是,我发现设备name、IP这些信息,我手动编码成二进制后在配置文件中居然筛查不到。在摸索的过程中,我想起了之前学过的关于字节序的知识,这里顺便整理复习一下。
在计算机中,单个字节的数据不存在字节序问题。比如 0x12 只占 1 个字节,无论放在哪里,它本身都还是 0x12。
字节序讨论的是:一个多字节数据在连续内存地址中,应该按什么顺序存放。
例如 32 位整数:
CodeBlock Loading...
它可以拆成 4 个字节:
CodeBlock Loading...
其中 0x12 是最高有效字节: MSB (Most Significant Byte)。0x78 是最低有效字节: LSB(Least Significant Byte)。
小端与大端
小端字节序,也就是 Little-endian:
最低有效字节放在最低内存地址处。
假设从地址 0x1000 开始存储 0x12345678,小端模式下是:
CodeBlock Loading...
从低地址到高地址看,顺序是:
CodeBlock Loading...
大端字节序,也就是 Big-endian:
最高有效字节放在最低内存地址处。
同样的数据在大端模式下是:
CodeBlock Loading...
从低地址到高地址看,顺序是:
CodeBlock Loading...
所以二者的本质区别就是:
低地址处放的是低有效字节,还是高有效字节。
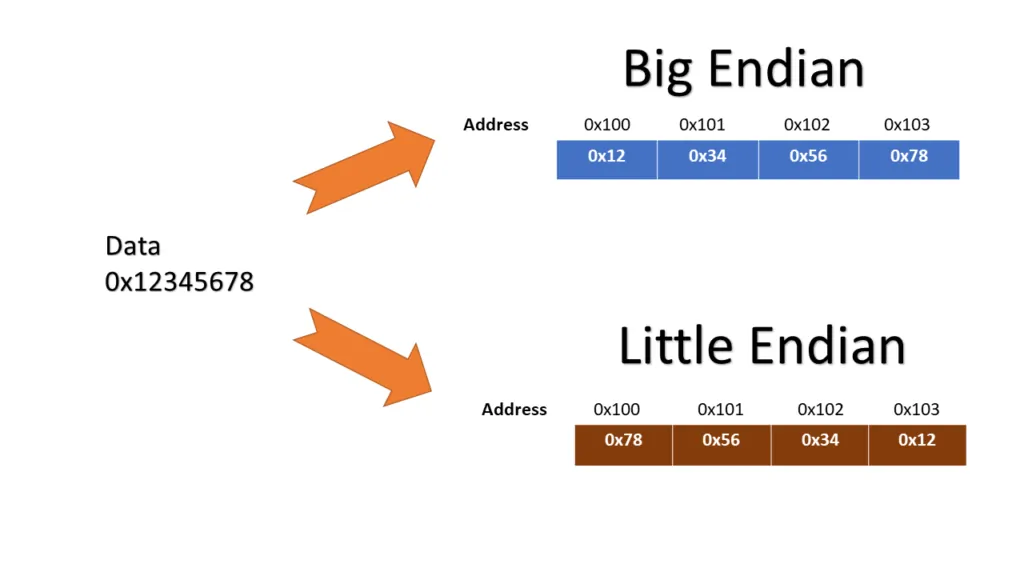
大端字节序、小端字节序在内存中的分布
字节序为什么存在
现代计算机的内存通常按字节寻址。也就是说,一个地址对应一个字节:
CodeBlock Loading...
但是一个 int32 需要 4 个字节,一个 int64 需要 8 个字节。只要一个数据需要占用多个地址,就必须约定这些字节和地址之间的对应关系。
因此,字节序主要影响的是:
CodeBlock Loading...
只要涉及“多字节数据 + 线性字节流”,就需要明确字节序。
字节序与 CPU 计算
一种常见说法是:"小端字节序有利于 CPU 计算"
这句话有一定道理,但容易被误解。
对于普通的 32 位或 64 位整数运算,CPU 通常会先把数据从内存加载到寄存器,再交给 ALU 计算。加载时,CPU 的 load 单元会按照当前架构的字节序,把内存中的字节组装成寄存器里的逻辑值。
CPU工作示意图
图片来自:https://cs.stanford.edu/people/eroberts/courses/soco/projects/2005-06/64-bit-processors/whatis2.html
例如,不管内存里是小端的:
CodeBlock Loading...
还是大端的:
CodeBlock Loading...
只要加载规则正确,寄存器里的数值都是:
CodeBlock Loading...
ALU 做加法、减法、移位、按位与时,处理的是寄存器中的位权重,而不是这个值之前在内存里的字节排列。因此在现代常见的定宽整数计算中,小端和大端通常不会带来明显的 ALU 性能差异。
小端真正方便的地方主要在低位优先处理。
早期或简单硬件中,如果数据总线宽度小于操作数宽度,CPU 可能需要分多次取数。加法的进位方向是从低位到高位,如果小端让最低有效字节先到达,那么硬件或微码就可以更自然地从低位开始处理。这个场景下,小端可能简化实现或降低等待。
但这不是“小端一定让 CPU 算得更快”。现代 CPU 有宽寄存器、缓存、加载单元和字节重排逻辑,普通定宽整数运算的性能通常不由大小端决定。
小端的优势
小端的核心优势是:低有效部分在低地址处。
例如 0x12345678 的小端布局是:
CodeBlock Loading...
如果从同一个起始地址读取不同宽度的数据,会得到:
CodeBlock Loading...
这意味着完整整数的起始地址,也正好是它低有效部分的起始地址。对底层二进制处理、部分读取、截断视角和多精度整数运算来说,这很方便。
这里要注意:高级语言里的类型转换,例如 (short)x,通常是语言层面的数值转换,不等于一定从内存同一地址重新读取 2 个字节。上面的例子讨论的是底层内存布局视角。
小端也适合大整数运算。几百位或几千位整数通常会拆成多个 32 位或 64 位块,也叫 limb。(limb 就是大整数的 “数字位”,只是基数是 2³² 或 2⁶⁴,而不是十进制的 10)。加法必须从最低 limb 开始,因为进位从低位传向高位:
CodeBlock Loading...
如果最低 limb 位于最低地址,程序就可以从低地址向高地址顺序遍历。这是一种算法和数据布局上的便利。
此外,x86、x86-64 以及现代常见操作系统环境大多采用小端,现实工程中的生态兼容性也很强。
大端的优势
大端的核心优势是:内存顺序和人类书写顺序一致。
例如 0x12345678 的大端布局是:
CodeBlock Loading...
这和十六进制数字的书写顺序相同。查看内存、分析协议、阅读十六进制 dump 时,大端更直观。
TCP/IP 中的“网络字节序”采用大端,很多网络协议和二进制格式也会明确指定字节序。跨平台通信时,不能默认发送方和接收方的 CPU 字节序相同,必须按协议规定进行编码和解码。
大端还有一个常见好处:对于固定宽度的无符号整数,大端字节序下按字节从前往后比较,结果和数值大小比较一致。例如:
CodeBlock Loading...
按字节比较时,00 00 00 02 小于 00 00 00 10。这对某些排序、索引和二进制键设计比较方便。需要注意,这个结论主要针对固定宽度的无符号整数;有符号整数和变长编码需要额外规则。
这个特性在存储系统中很实用。很多 B+ 树、LSM Tree 或有序 KV 存储的底层比较器,看到的并不是高级语言里的结构体,而是一段连续的 key 字节数组。如果 key 的编码方式设计得好,底层就可以直接按字节序比较两个 key。
例如一个复合索引包含:
CodeBlock Loading...
如果要比较两条记录的大小,常规的高级语言做法是写一个结构体比较函数:
CodeBlock Loading...
这种代码有什么问题?
- CPU 分支预测失败:里面大量的
if-else属于条件分支。在 B+ 树动辄几百万次的比较中,分支预测失败会极大地拖慢 CPU 速度。 - 缺乏通用性:如果用户改了索引结构,增加了一个字段,你就得重新写一个比较函数,或者用复杂的反射/元编程机制,底层性能大打折扣。
但如果把每个整数都编码成固定宽度的大端字节序,再按字段顺序拼接:
CodeBlock Loading...
那么两个 key 的字节序比较,就等价于按 (Age, Score, ID) 依次比较:
CodeBlock Loading...
如果 Age 不同,第 1 个字节就能分出大小;如果 Age 相同,比较会自然继续到 Score;如果 Score 也相同,再继续比较 ID。这就是一种保序编码:编码后的字节序关系保持原始数值或元组的排序关系。
这样做的好处是,底层索引结构可以使用更通用的字节数组比较器,而不必为每种复合索引都写一套字段级比较逻辑。实际系统中还需要处理更多细节,例如有符号整数、浮点数、字符串排序规则、NULL、变长字段和降序索引等;这些类型通常需要额外的编码规则,不能简单地直接拼接原始内存内容。
字节序不等于 bit 顺序
另一个常见疑问是:
如果字节顺序可以反过来,为什么 bit 顺序不一起反过来?
原因是大小端讨论的是“字节之间的顺序”,不是“一个字节内部 bit 的顺序”。
内存通常按字节寻址,CPU 可以访问:
CodeBlock Loading...
但普通程序通常不能把每个 bit 当成独立内存地址访问。因此大小端关心的是:
CodeBlock Loading...
而不是:
CodeBlock Loading...
一个字节内部当然有 bit0、bit1、bit2 等逻辑编号,CPU 的移位、加法、按位运算都依赖这些位权重。但这些位权重由硬件线路、寄存器编号和指令语义定义,不属于普通字节序问题。
如果把一个字节内部的 bit 也反转,数值本身会改变:
CodeBlock Loading...
而大小端只是改变多个字节在地址中的排列,不会改变每个字节内部的内容。
总结
| 对比项 | 小端字节序 | 大端字节序 |
|---|---|---|
| 英文 | Little-endian | Big-endian |
| 低地址存放 | 最低有效字节 | 最高有效字节 |
0x12345678 的内存顺序 | 78 56 34 12 | 12 34 56 78 |
| 阅读直观性 | 不如大端直观 | 更接近书写顺序 |
| 低位截断和部分读取 | 更方便 | 需要偏移到低有效部分 |
| 多精度低位运算 | 更自然 | 通常要从高地址方向处理低位 |
| 网络字节序 | 不是传统网络字节序 | TCP/IP 网络字节序 |
| 现代 PC/服务器生态 | 常见 | 相对少见 |
小端和大端都是多字节数据的排列约定,本身没有绝对优劣,主要是适用场景的区别。
小端把最低有效字节放在最低地址处,更适合低位截断、部分读取、低位优先处理和多精度整数运算。现代主流 PC 和服务器生态也主要使用小端。
大端把最高有效字节放在最低地址处,内存顺序更接近人类书写顺序,也常见于网络协议和一些二进制格式。
真正需要记住的是:字节序主要影响数据在内存、文件、网络和外设中的解释方式。CPU 的 ALU 在计算时处理的是寄存器中的逻辑值;只要数据被正确加载,普通定宽整数运算通常不会因为小端或大端而产生本质性能差异。